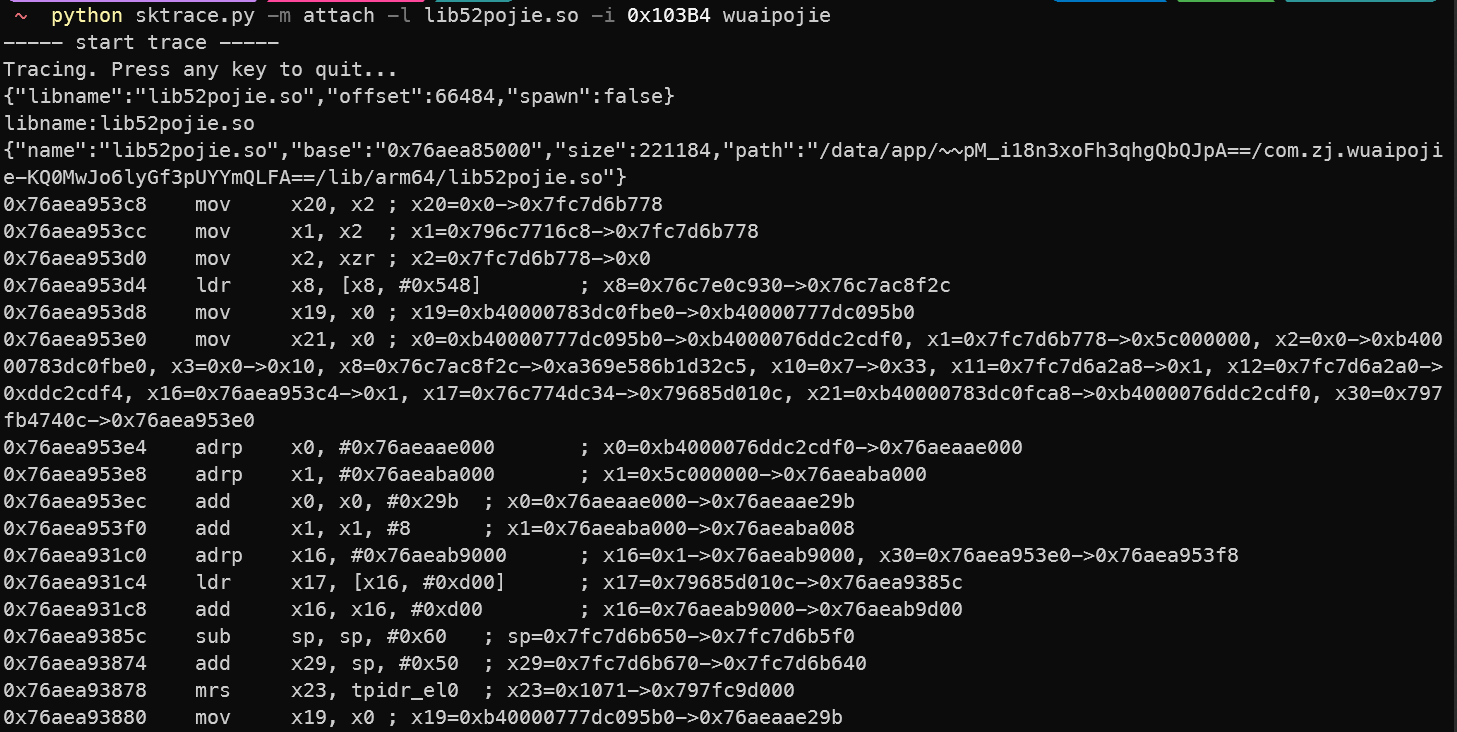
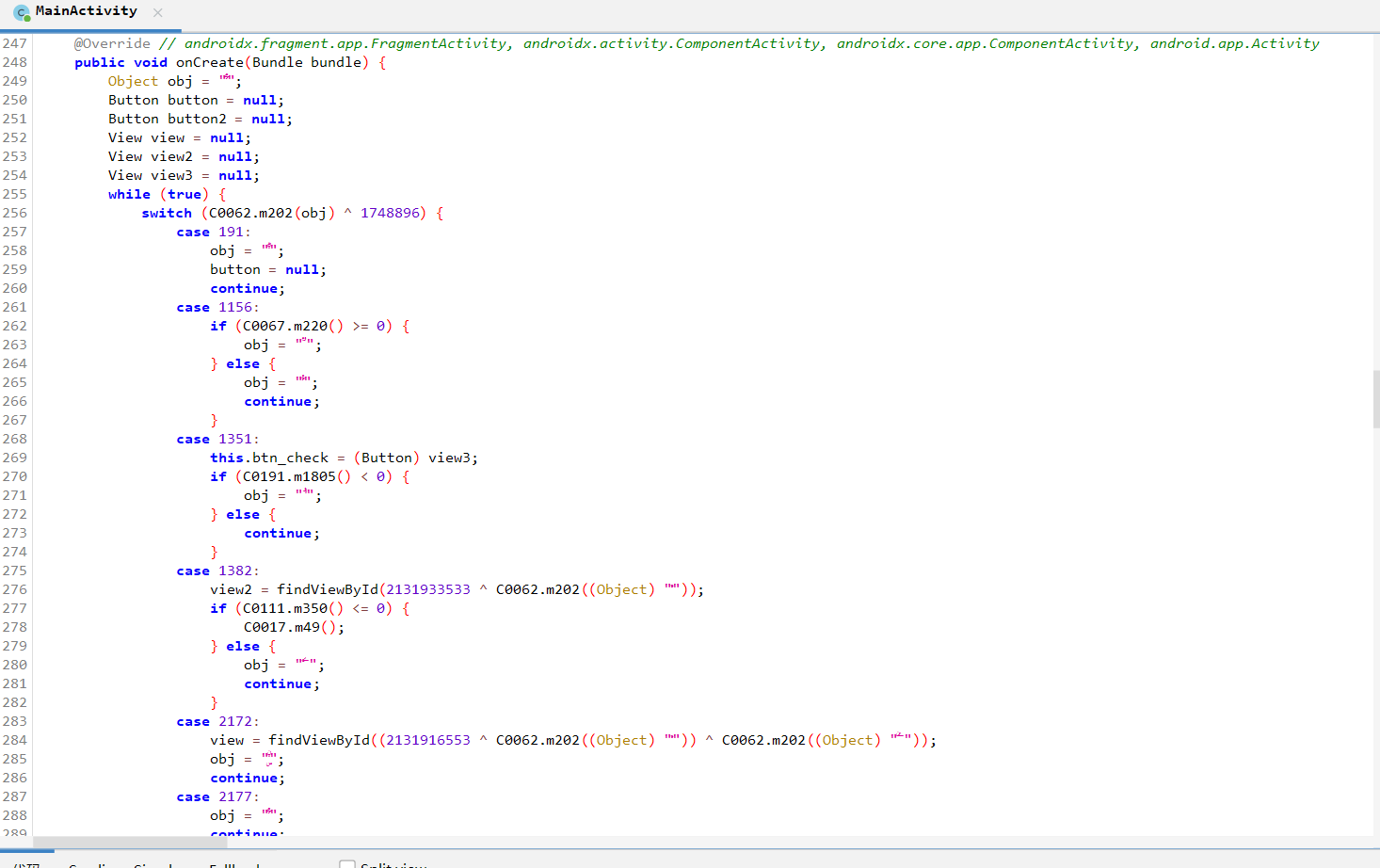
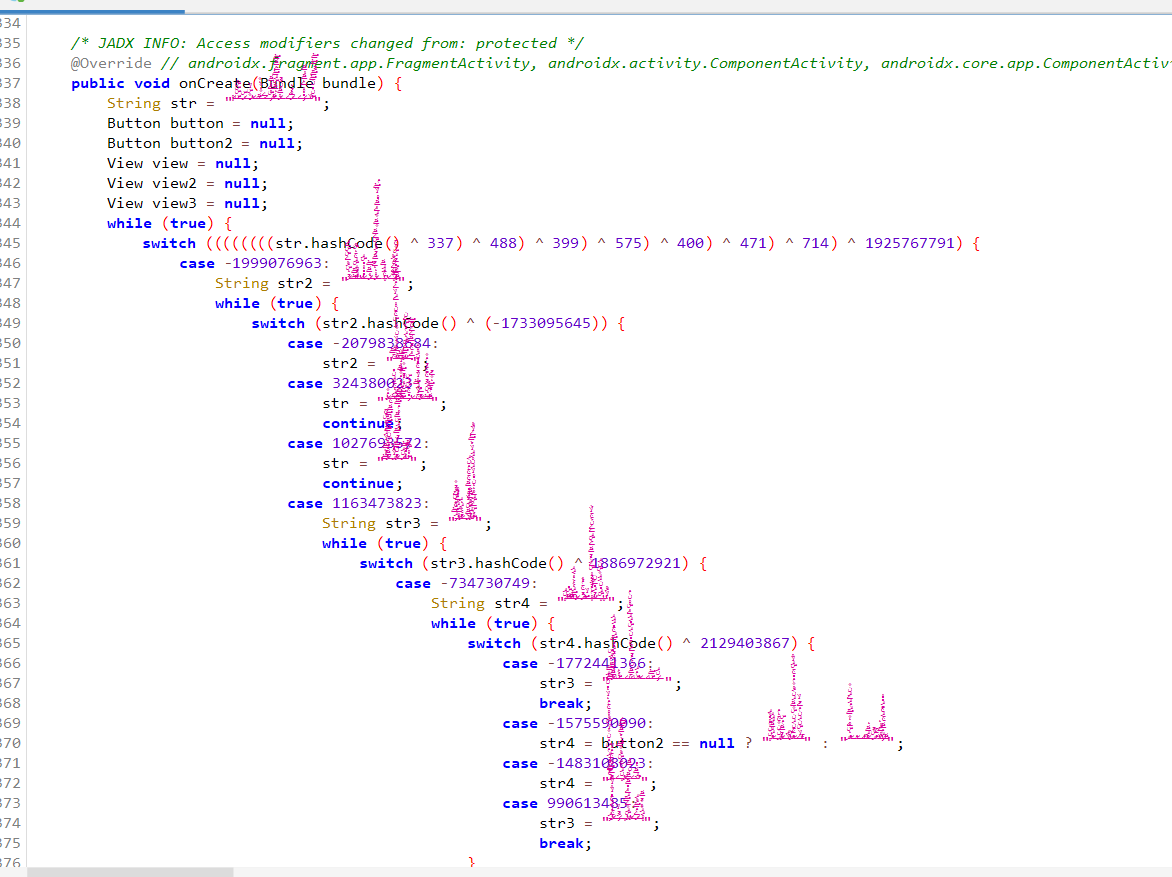
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
| using namespace std;
string packname;
string origpath;
string fakepath;
int (*orig_open)(const char *pathname, int flags, ...);
int (*orig_openat)(int,const char *pathname, int flags, ...);
FILE *(*orig_fopen)(const char *filename, const char *mode);
static long (*orig_syscall)(long number, ...);
int (*orig__NR_openat)(int,const char *pathname, int flags, ...);
void* (*orig_dlopen_CI)(const char *filename, int flag);
void* (*orig_dlopen_CIV)(const char *filename, int flag, const void *extinfo);
void* (*orig_dlopen_CIVV)(const char *name, int flags, const void *extinfo, void *caller_addr);
static inline bool needs_mode(int flags) {
return ((flags & O_CREAT) == O_CREAT) || ((flags & O_TMPFILE) == O_TMPFILE);
}
bool startsWith(string str, string sub){
return str.find(sub)==0;
}
bool endsWith(string s,string sub){
return s.rfind(sub)==(s.length()-sub.length());
}
bool isOrigAPK(string path){
if(path==origpath){
return true;
}
return false;
}
//该函数的功能是在打开一个文件时进行拦截,并在满足特定条件时将文件路径替换为另一个路径
//fake_open 函数有三个参数:
//pathname:一个字符串,表示要打开的文件的路径。
//flags:一个整数,表示打开文件的方式,例如只读、只写、读写等。
//mode(可选参数):一个整数,表示打开文件时应用的权限模式。
int fake_open(const char *pathname, int flags, ...) {
mode_t mode = 0;
if (needs_mode(flags)) {
va_list args;
va_start(args, flags);
mode = static_cast<mode_t>(va_arg(args, int));
va_end(args);
}
//LOGI("open, path: %s, flags: %d, mode: %d",pathname, flags ,mode);
string cpp_path= pathname;
if(isOrigAPK(cpp_path)){
LOGI("libc_open, redirect: %s, --->: %s",pathname, fakepath.data());
return orig_open("/data/user/0/com.zj.wuaipojie/files/base.apk", flags, mode);
}
return orig_open(pathname, flags, mode);
}
//该函数的功能是在打开一个文件时进行拦截,并在满足特定条件时将文件路径替换为另一个路径
//fake_openat 函数有四个参数:
//fd:一个整数,表示要打开的文件的文件描述符。
//pathname:一个字符串,表示要打开的文件的路径。
//flags:一个整数,表示打开文件的方式,例如只读、只写、读写等。
//mode(可选参数):一个整数,表示打开文件时应用的权限模式。
//openat 函数的作用类似于 open 函数,但是它使用文件描述符来指定文件路径,而不是使用文件路径本身。这样,就可以在打开文件时使用相对路径,而不必提供完整的文件路径。
//例如,如果要打开相对于当前目录的文件,可以使用 openat 函数,而不是 open 函数,因为 open 函数只能使用绝对路径。
//
int fake_openat(int fd, const char *pathname, int flags, ...) {
mode_t mode = 0;
if (needs_mode(flags)) {
va_list args;
va_start(args, flags);
mode = static_cast<mode_t>(va_arg(args, int));
va_end(args);
}
LOGI("openat, fd: %d, path: %s, flags: %d, mode: %d",fd ,pathname, flags ,mode);
string cpp_path= pathname;
if(isOrigAPK(cpp_path)){
LOGI("libc_openat, redirect: %s, --->: %s",pathname, fakepath.data());
return orig_openat(fd,fakepath.data(), flags, mode);
}
return orig_openat(fd,pathname, flags, mode);
}
FILE *fake_fopen(const char *filename, const char *mode) {
string cpp_path= filename;
if(isOrigAPK(cpp_path)){
return orig_fopen(fakepath.data(), mode);
}
return orig_fopen(filename, mode);
}
//该函数的功能是在执行系统调用时进行拦截,并在满足特定条件时修改系统调用的参数。
//syscall 函数是一个系统调用,是程序访问内核功能的方法之一。使用 syscall 函数可以调用大量的系统调用,它们用于实现操作系统的各种功能,例如打开文件、创建进程、分配内存等。
//
static long fake_syscall(long number, ...) {
void *arg[7];
va_list list;
va_start(list, number);
for (int i = 0; i < 7; ++i) {
arg[i] = va_arg(list, void *);
}
va_end(list);
if (number == __NR_openat){
const char *cpp_path = static_cast<const char *>(arg[1]);
LOGI("syscall __NR_openat, fd: %d, path: %s, flags: %d, mode: %d",arg[0] ,arg[1], arg[2], arg[3]);
if (isOrigAPK(cpp_path)){
LOGI("syscall __NR_openat, redirect: %s, --->: %s",arg[1], fakepath.data());
return orig_syscall(number,arg[0], fakepath.data() ,arg[2],arg[3]);
}
}
return orig_syscall(number, arg[0], arg[1], arg[2], arg[3], arg[4], arg[5], arg[6]);
}
//函数的功能是获取当前应用的包名、APK 文件路径以及库文件路径,并将这些信息保存在全局变量中
//函数调用 GetObjectClass 和 GetMethodID 函数来获取 context 对象的类型以及 getPackageName 方法的 ID。然后,函数调用 CallObjectMethod 函数来调用 getPackageName 方法,获取当前应用的包名。最后,函数使用 GetStringUTFChars 函数将包名转换为 C 字符串,并将包名保存在 packname 全局变量中
//接着,函数使用 fakepath 全局变量保存了 /data/user/0/<packname>/files/base.apk 这样的路径,其中 <packname> 是当前应用的包名。
//然后,函数再次调用 GetObjectClass 和 GetMethodID 函数来获取 context 对象的类型以及 getApplicationInfo 方法的 ID。然后,函数调用 CallObjectMethod 函数来调用 getApplicationInfo 方法,获取当前应用的 ApplicationInfo 对象。
//它先调用 GetObjectClass 函数获取 ApplicationInfo 对象的类型,然后调用 GetFieldID 函数获取 sourceDir 字段的 ID。接着,函数使用 GetObjectField 函数获取 sourceDir 字段的值,并使用 GetStringUTFChars 函数将其转换为 C 字符串。最后,函数将 C 字符串保存在 origpath 全局变量中,表示当前应用的 APK 文件路径。
//最后,函数使用 GetFieldID 和 GetObjectField 函数获取 nativeLibraryDir 字段的值,并使用 GetStringUTFChars 函数将其转换为 C 字符串。函数最后调用 LOGI 函数打印库文件路径,但是并没有将其保存在全局变量中。
extern "C" JNIEXPORT void JNICALL
Java_com_zj_wuaipojie_util_SecurityUtil_hook(JNIEnv *env, jclass clazz, jobject context) {
jclass conext_class = env->GetObjectClass(context);
jmethodID methodId_pack = env->GetMethodID(conext_class, "getPackageName",
"()Ljava/lang/String;");
auto packname_js = reinterpret_cast<jstring>(env->CallObjectMethod(context, methodId_pack));
const char *pn = env->GetStringUTFChars(packname_js, 0);
packname = string(pn);
env->ReleaseStringUTFChars(packname_js, pn);
//LOGI("packname: %s", packname.data());
fakepath= "/data/user/0/"+ packname +"/files/base.apk";
jclass conext_class2 = env->GetObjectClass(context);
jmethodID methodId_pack2 = env->GetMethodID(conext_class2,"getApplicationInfo","()Landroid/content/pm/ApplicationInfo;");
jobject application_info = env->CallObjectMethod(context,methodId_pack2);
jclass pm_clazz = env->GetObjectClass(application_info);
jfieldID package_info_id = env->GetFieldID(pm_clazz,"sourceDir","Ljava/lang/String;");
auto sourceDir_js = reinterpret_cast<jstring>(env->GetObjectField(application_info,package_info_id));
const char *sourceDir = env->GetStringUTFChars(sourceDir_js, 0);
origpath = string(sourceDir);
LOGI("sourceDir: %s", sourceDir);
jfieldID package_info_id2 = env->GetFieldID(pm_clazz,"nativeLibraryDir","Ljava/lang/String;");
auto nativeLibraryDir_js = reinterpret_cast<jstring>(env->GetObjectField(application_info,package_info_id2));
const char *nativeLibraryDir = env->GetStringUTFChars(nativeLibraryDir_js, 0);
LOGI("nativeLibraryDir: %s", nativeLibraryDir);
//LOGI("%s", "Start Hook");
//启动hook
void *handle = dlopen("libc.so",RTLD_NOW);
auto pagesize = sysconf(_SC_PAGE_SIZE);
auto addr = ((uintptr_t)dlsym(handle,"open") & (-pagesize));
auto addr2 = ((uintptr_t)dlsym(handle,"openat") & (-pagesize));
auto addr3 = ((uintptr_t)fopen) & (-pagesize);
auto addr4 = ((uintptr_t)syscall) & (-pagesize);
//解除部分机型open被保护
mprotect((void*)addr, pagesize, PROT_READ | PROT_WRITE | PROT_EXEC);
mprotect((void*)addr2, pagesize, PROT_READ | PROT_WRITE | PROT_EXEC);
mprotect((void*)addr3, pagesize, PROT_READ | PROT_WRITE | PROT_EXEC);
mprotect((void*)addr4, pagesize, PROT_READ | PROT_WRITE | PROT_EXEC);
DobbyHook((void *)dlsym(handle,"open"), (void *)fake_open, (void **)&orig_open);
DobbyHook((void *)dlsym(handle,"openat"), (void *)fake_openat, (void **)&orig_openat);
DobbyHook((void *)fopen, (void *)fake_fopen, (void**)&orig_fopen);
DobbyHook((void *)syscall, (void *)fake_syscall, (void **)&orig_syscall);
}
|